
Shuffling image quadrants
Image processing is an important area in computer vision. It covers a whole range of topics, from being able to detect cats in images to the algorithms that support popular image editing programs such as photoshop. In experimental research, we occassionaly also require some image processing to manipulate images in certain ways.
One example of such a manipulation is to take an image and divide it into four equal parts. A new image is then composed by taking this part and putting them back in the image, but at a different location than it was originally. The result of this procedure is shown in the image below. For one image, one could probably get away by doing this in Paint. But if you have to do this for many images (and take into account that the same procedure can be applied to the parts themselves), being able to do this with some programming code will definitely save you some time!

Creating the quadrant coordinates
We will use the Python Image Library (PIL) to load and save the images. The actual manipulation will be done by converting a loaded image into a nump array and using array slicing operations to extract the quadrants and place them back into the original image. As a first step here, I create for each quadrant a list with four elements. The first two elements are the x and y coordinates of the top left corner of the quadrant. The final two elements are the x and y coordinates for the bottom right corner of the quadrant.
q1 = [0, 0, int(height/2), int(width/2)]
q2 = [0, int(width/2), int(height/2), width]
q3 = [int(height/2), 0, height, int(width/2)]
q4 = [int(height/2), int(width/2), height, width]It always helps to have a good mental representation of what these numbers mean. The picture below shows that when treating the image as a numpy array, we can take the upper left corner as the origin. This is therefore also the coordinate of the top left corner of the first quadrant. Since we are splitting the image in half, the coordinate for the bottom right corner of the first quadrant corresponds to the height and the width divided by.

Selecting the quadrants
Once we have the coordinates, we can select the image quadrants by using the array slicing operations on the image array using the coordinates we have just created:
im_q1 = im[q1[0]: q1[2], q1[1]: q1[3]]
im_q2 = im[q2[0]: q2[2], q2[1]: q2[3]]
im_q3 = im[q3[0]: q3[2], q3[1]: q3[3]]
im_q4 = im[q4[0]: q4[2], q4[1]: q4[3]]Reassembling the image
The final step is to create a new empty image. Within this image we can use the coordinates we have defined previously to select a quadrant, and then assign to this quadrant one of the extracted quadrants:
shuffled_image = np.zeros(im.shape, dtype=np.uint8)
shuffled_image[q1[0]: q1[2], q1[1]: q1[3]] = im_q2
shuffled_image[q2[0]: q2[2], q2[1]: q2[3]] = im_q4
shuffled_image[q3[0]: q3[2], q3[1]: q3[3]] = im_q3
shuffled_image[q4[0]: q4[2], q4[1]: q4[3]] = im_q1There is just one tiny little problem
The procedure above works fine as long as the input dimensions of the image you are dealing with are even. If you try to apply this procedure to an image in which one or both of the dimensions are uneven, you will probably get an error indicating that the dimensions of the quadrant that you want to fill in within the new image do not match the dimensions of the quadrant you have extracted. The reason for this error is actually quite simple, and provides an interesting opportunity to learn how the slicing operations work exactly.
If you go back to the first part where we calculate the coordinates for the quadrants, you will see that part of the information comes from dividing the height and the width by two. If your dimension is even, this works as expected. To illustrate this, let's assume your image has a width of 6 pixels. Half of this is 3. As illustrated in the image below, this will yield the same number of pixels for both parts if you use this value to split your dimension:
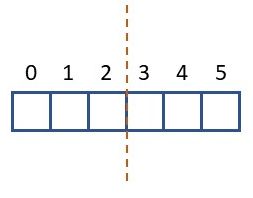
However, if your dimension is uneven (let's say 5 pixels), then halving this value and rounding this gives 2. But if you use this value in the slicing operation you get a different number of pixels for each half:
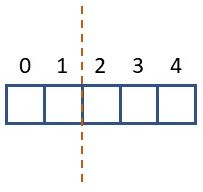
One possible solution is to use a different numbers for the center of your image if the corresponding dimension is uneven. In the example above, we could decide to take the first three pixels in stead of only the first two for the left half, and then again use the same number of pixels for the right half. This is is illustrated in the image below, where for the left half you would take the pixels up to the green line, and for the right half you would take the pixels starting from the red line.
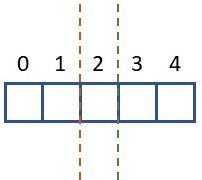
This can be translated into Python code as follows. We define a variable horizontal_midline_start which indicates the pixel from which we start counting to select the second half. For this we can simply divide the size of the dimension by two and round it. We also define a value horizontal_midline_end, which represents how many pixels we take in the left part. Again we can divide the size of the dimension by two and round it, but if the dimension is uneven we add one pixel.
horizontal_midline_start = int(width/2)
if width%2 == 0:
horizontal_midline_end = int(width/2)
else:
horizontal_midline_end = int(width/2) + 1
vertical_midline_start = int(height/2)
if height%2 == 0:
vertical_midline_end = int(height/2)
else:
vertical_midline_end = int(height/2) + 1
q1 = [0, 0, vertical_midline_end, horizontal_midline_end]
q2 = [0, horizontal_midline_start, vertical_midline_end, width]
q3 = [vertical_midline_start, 0, height, horizontal_midline_end]
q4 = [vertical_midline_start, horizontal_midline_start, height, width]A consequence of this procedure is of course that you have some overlap between pixels in each quadrant, but it does give you quadrants that are all equal in size and therefore allows you to shuffle them freely.
Full code
from PIL import Image
import numpy as np
im = Image.open(r'my_image.jpg')
im = np.array(im, dtype=np.uint8)
height, width = im.shape[:2]
horizontal_midline_start = int(width/2)
if width%2 == 0:
horizontal_midline_end = int(width/2)
else:
horizontal_midline_end = int(width/2) + 1
vertical_midline_start = int(height/2)
if height%2 == 0:
vertical_midline_end = int(height/2)
else:
vertical_midline_end = int(height/2) + 1
q1 = [0, 0, vertical_midline_end, horizontal_midline_end]
q2 = [0, horizontal_midline_start, vertical_midline_end, width]
q3 = [vertical_midline_start, 0, height, horizontal_midline_end]
q4 = [vertical_midline_start, horizontal_midline_start, height, width]
im_q1 = im[q1[0]: q1[2], q1[1]: q1[3]]
im_q2 = im[q2[0]: q2[2], q2[1]: q2[3]]
im_q3 = im[q3[0]: q3[2], q3[1]: q3[3]]
im_q4 = im[q4[0]: q4[2], q4[1]: q4[3]]
shuffled_image = np.zeros(im.shape, dtype=np.uint8)
shuffled_image[q1[0]: q1[2], q1[1]: q1[3]] = im_q2
shuffled_image[q2[0]: q2[2], q2[1]: q2[3]] = im_q4
shuffled_image[q3[0]: q3[2], q3[1]: q3[3]] = im_q3
shuffled_image[q4[0]: q4[2], q4[1]: q4[3]] = im_q1
shuffled_image = Image.fromarray(shuffled_image)
shuffled_image.save(r'my_shuffled_image.jpg')